
mysql的执行流程
先看个大概
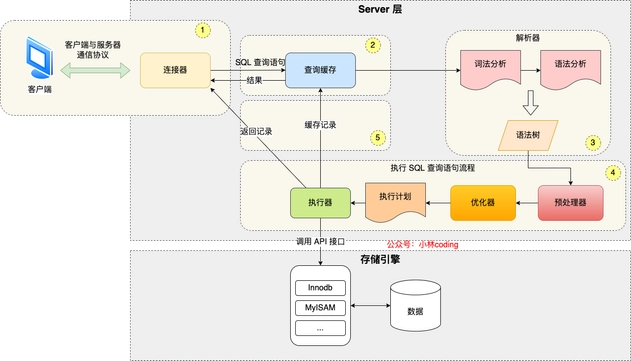
mysql大致分为两层,server层和储存引擎层,简单说储存引擎层就负责数据的存取,其他事情都归server层负责
- server层:与客户端建立连接,分析执行sql。连接器-缓存-解析器-预处理器-优化器-执行、还有其他函数,包括时间日期、数学、加密的一些函数,其他功能:储存过程、触发器、视图
- 储存引擎层:支持多个引擎,默认的引擎是InnoDB,其索引类型是B+树,主键索引和二级索引都是B+树实现的
以上是简单认识接下来看一下具体流程
第一步:连接器
连接命令 mysql -h ip -u name -p 连接本地sql服务的话,-h ip是可以省略的
客户端与服务器的是通过TCP实现的,mysql服务默认在3306号端口上运行。
当用户权限被修改时,用户连接存在,那么新权限将在下一次连接时生效。
查看MySQL服务现在存在多少个连接
show processlist
手动断开连接: kill connection + id
既然连接器是通过TCP实现的,那么就会有长连接和短链接,一般使用长连接,但是长连接长期不断开积累过多就会出现问题,内存占用问题
如何解决?
- 服务器定期断
- 客户端主动重置
mysql_reset_connection()函数可以是连接恢复到刚创建的样子
第二步:查询缓存
查询缓存只针对查询,select语句,缓存中以键值对的形式储存select语句和查询结果。
这里缓存与大部分缓存的工作原理大同小异,查询语句命中缓存,那就直接返回已有的查询结果,没有命中就去正常执行,返回查询结果,再把结果放到缓存中。
我们简单想一下这个缓存的命中率会不会很高,首先重复的select语句会被应用频繁发送吗?如果数据库不会变动的话,一次查询结果可以长期使用,但实际上,我每一次都要去查数据库不就是因为数据库变动了吗?既然数据库会经常变动,那缓存不就扯淡吗?相应的表一更新,涉及到的缓存统统就没用了。
实际上,mysql8之后就放弃掉了server层的查询缓存,我看了一下我本地的5版本,默认也是关闭的
第三步:解析SQL
如果读者学过编译原理的话,这地地方就很容易看懂。
gcc的编译流程是什么?预处理 编译 汇编 链接 执行,其中还编译又包括词法分析,语法分析,优化,妈的忘记完了说是
这里解析器把sql语句解析成语法树,但是不会管表和字段是不是合理的,存不存在,只会管语法错误,语法树生成不出来,自然就是原错误了。
第四步:执行SQL
- prepare 阶段,也就是预处理阶段;
- optimize 阶段,也就是优化阶段;
- execute 阶段,也就是执行阶段;
预处理
- 检查表和字段的值是否合理
- 将*替换掉,自然是替换成所有的列
优化器
生成执行计划,选择索引,默认储存引擎是使用B+树编制索引的,但是这个数据结构我也不了解
执行器
三种查询方式
- 主键索引查询
- 全表扫描
- 索引下推